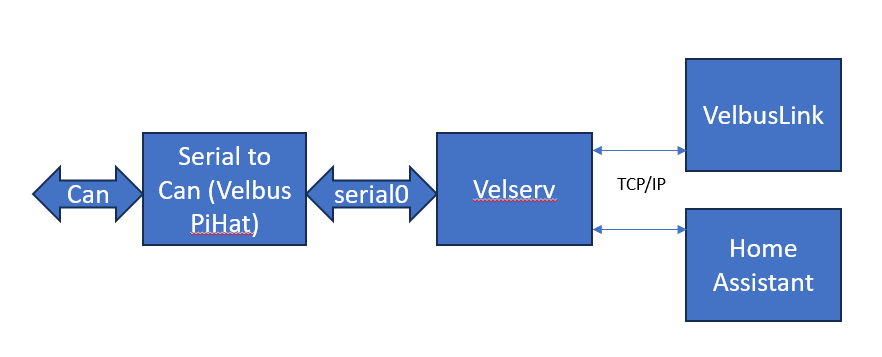
I have a Velbus integration with Home Assistant which works perfect with limited number of modules. However when I connect to my actual installation (= 69 modules) I am missing a number of modules. Is any body else experiencing the same problem? I connect to velbus over Velserv and my own canBus interface (PIhat described elsewhere on this forum) but the same problem occurs when I connect directly on the PI usb with VMBUSB1 module.
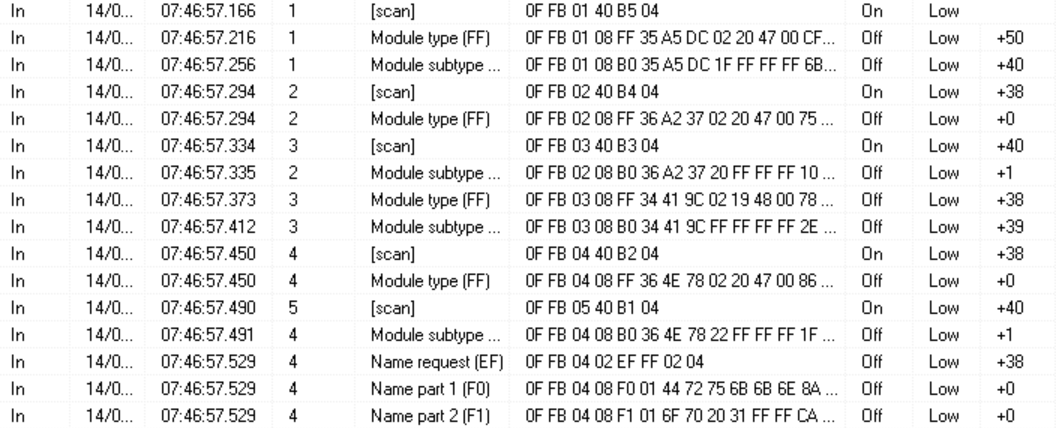
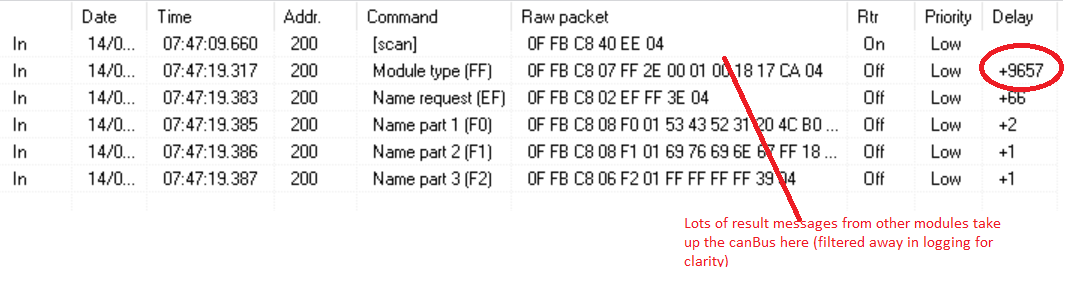
This configuration allows VelbusLink to act as a canBus sniffer with extensive timing and filtering options for diagnostics. Via this logging it is easy to see that a (re)load of the Velbus integration scans every module address followed by getting channel names (equivalent to VelbusLink scan). This causes extensive use of the canBus resulting in some delay in the modules response messages. Because the module scan sequence does not pause for results, the traffic and delay on de canBus increases significant with higher module numbers because multiple modules are trying to send theire response messages at the same time.
This delay by itself should not be a problem. The same occurs when executing a scan in VelbusLink but VelbusLink handles this delay without problems. Could this be a problem for the Home Assistant integration ? Any other idea ? Is (Python ?) code of velbus integration somewhere available on git for better understanding of implementation ?
Suggestion 1: restart (module) timeout when any message received from scanned module and optional stop timeout when config load complete.
Suggestion 2: set timeout to higher value
Suggestion 3: just keep fixed wait time but continue handling config messages even after timeout has occured. I have the impression that VelbusLink is doing that (the scan dialog is closed when scanning but the config tree continues to be updated long after the dialog is closed, also VelbusLink captures and handles config messages triggered from Home Assistant without a scan request in VelbusLink)
To my opinion suggestion 1 would be the preferred solution (fastest and avoids saturating the canBus). Setting a higher timeout value seems easiest but will slow down the load a bit especially in small installations with few modules (not really a big deal I assume). Suggestion 3 seems also ok, but I have no idea if this is easy to implement … and the risk still exist to saturate the canBus.
you would be really welcome to help out, i’m really limited by the time i can put into this project at the moment, so not sure when i will be able to start on it
I was rather thinking about a financial contribution … because I am really a Windows guy (C++, C#, Visual Studio, TFS, …) and an embedded electronics hobbyist.
Still I would be happy to invest time in python/linux development if someone could give me a jump start in the development cycle / tools. Is it an option we can meet in person? But again this will take some of your time … just let me know if this is an option.
Another simple (temporary) option could be just to double the fixed timeout. This would also double the intialisation time but I could live with that.
I had a short look at the code and from my knowledge the problem could be solved by reorganising a little bit the code of async def scan(self) → None:
The code starts by sending the ModuleTypeRequest to all modules in burst (which already puts the canBus under stress) afterwards the total timeout is calculated from the number of modules.
I would propose to change the code to a more sequential approach
In semi code it would look like
for addr in range(1, 255)
send request module type (ModuleTypeRequestMessage(addr))
wait for type message received within short timeout
if received module type info
query module info and state
wait for loading module info
else
module is not available, just continue with next module
Although the sequential code looks slower at first sight I think it would actually be a lot faster. Because there is only a single ModuleTypeRequestMessage at a time we should get the response pretty fast (no saturated canBus). So in a very short timeout we can decide the presence of a module.
Does this make sense … or did I misunderstood the code?
controller.log (10.9 KB) handler.log (9.6 KB)
Hi, I implemented the sequential approach in the uploaded files ‘handler.log’ and ‘controller.log’ (I renamed them from *.py to *.log to be able to upload the files).
All proposed changes are marked with ‘lgor’. If you agree with new approach I could fork at git … but I don’t know how to commit, build, test …
So far all good, but the test code still runs in a virtual python environment with Visual Code and uses the cereal example load_modules(). This is perfect for testing because it runs completely independent of Home Assistant. However now is the time to activate the forked integration into Home Assistant but I cannot figure out how to do it. I tried:
copying the velbusio integration tree under hass/custom_components but the integration is not loaded and there seems to be nothing in the logs
load the custum integrations with HACS but structure seems to be not HACS compliant
PIP INSTALL from local files, PYPI, my git fork … all failed
installed standard Velbus integration with to hope to be able to overwrite new py files but didn’t find the files (I guess a binary build is made ?)
Velbus seems integrated in HAS (no custom integration or HACS integration). Should I use another way to install the fork? Please, any help, hint, reading much appreciated !
fyi: I am running Home Assistant Docker with HACS + Velserv + Velbus PI hat + Luxtronix, Huawai, … on a PI4
Still many thanks to cereal for putting me on the right dev track with load_modules. Hopefully we can move this fork back to the master when there is more time available
How did you solve this issue? I’m currently running Home Assistant Container on a Raspberry Pi 3B using the (Raspberry Pi Lite) OS. I’m using docker compose with the ha-compose.yml file provided.
On the same RPi I’ve also installed the velbus-tcp snap package so that I connect to my Velbus installation using TCP/IP through either VelbusLink or Home Assistant. Connection through VelbusLink works flawless as I can scan, find and operate all my modules. However, when I add the Velbus integration on HA via the TCP/IP connection, only 11 of my devices are found. Thus, I’m missing a lot of modules, such as my relais and my roller shutter modules.
I’ve already tried reloading the velbus hub through the HA dashboard and I’ve also tried using the “velbus.clear_cache” and “velbus.scan” actions through HA scripts. Nothing seems to add these missing modules, so if anybody has a clue on what to do next, that’d be much appreciated!
(I’m also tagging @MDAR as he is heavily involved in the velbus tcp snap package) ha-compose.log (375 Bytes)